Previsioni AI-powered: la regressione lineare
L'intelligenza artificiale, per come la conosciamo oggi, è fondamentalmente un applicazione avanzata di concetti statistici. Quando l'AI prevede fenomeni basandosi sui dati, non fa altro che applicare la statistica per inferire i valori più probabili.
La regressione lineare è una delle tecniche statistiche più semplici per prevedere un valore. Usiamo un po' di statistica, un po' di programmazione e qualche grafico per spiegare in breve come fanno le AI a fare una previsione.
Previsioni nel motorsport
Immaginiamo uno scenario d'esempio: prevediamo i risultati della prossima stagione di Formula Promezio, una categoria inferiore del motorsport creata per l'occasione. Per i Team di Formula Promezio c'è una correlazione diretta tra il fatturato e i punti vinti durante la stagione.
Creiamo dei dati sintetici che rappresentano fatturati e punti ottenuti da tutti i team nelle ultime 10 stagioni. Se sei interessato alla parte tecnica, il codice per questo esempio è disponibile a questo indirizzo. Si tratta di un notebook python che può essere eseguito direttamente all'interno del browser.
In questo grafico il risultato di questa generazione:
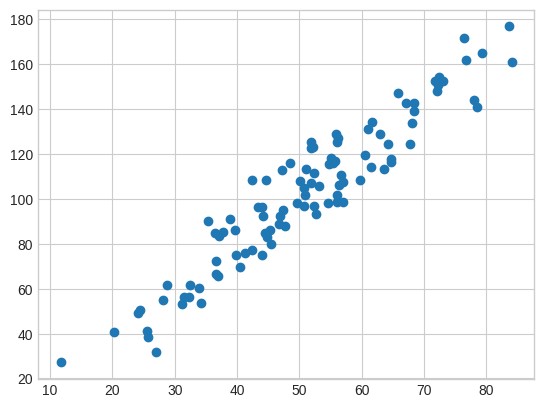
Dividiamo questi dati sintetici in due gruppi, il primo sarà usato per il training del modello, il secondo come gruppo di controllo per verificare le performance che riusciremo ad ottenere. Fatto lo split alleniamo il nostro modello usando una libreria che si chiama sklearn.
Per valutare le performance di un modello si usa il coefficiente R^2, noto anche come coefficiente di determinazione. Questo valore è una misura statistica che indica la percentuale della varianza della variabile dipendente che è prevedibile dalla variabile indipendente in un modello di regressione. In altre parole, R^2 misura quanto bene i valori osservati sono replicati dai valori previsti dal modello, basandosi sulla proporzione della varianza totale dei valori.
Valori vicini a 1 indicano che una grande porzione della varianza nei dati è spiegata dal modello. Più il valore di R^2 è vicino a 1, meglio è in termini di capacità del modello di spiegare la varianza. Valori molto bassi indicano che il modello non spiega bene la varianza dei dati; potrebbe non catturare adeguatamente le relazioni tra variabili o potrebbe essere troppo semplice.
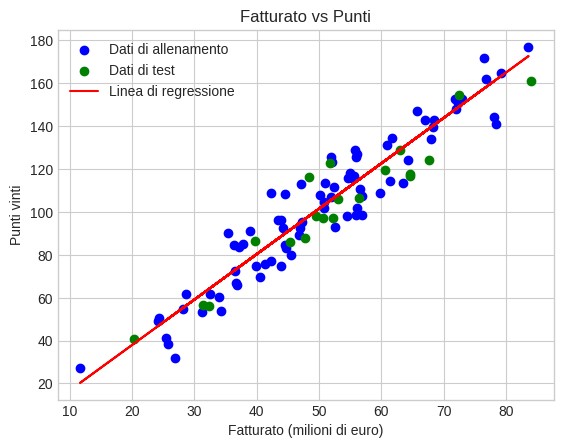
Nell'esempio abbiamo ottenuto uno score di 0.89, un valore niente male per un modello di base.
Proviamo a visualizzare il modello su un grafico. Qui di seguito vedete i dati di test come punti blu, i dati di test cpome punti verdi e il modello di regressione come una linea rossa. Questa linea permette di prevedere il numero di punti che un team guadagnerà in una stagione basandosi soltanto sul fatturato dell'anno precedente.
I modelli di previsione delle DataRoom di Promezio dedicate ai motorsport utilizzano questi principi di base. Le AI utilizzate sono più complesse, perchè le relazioni tra i dati non sono lineari e i dati dai quali inferire i risultati sono decisamente molti di più. Nello maggior parte dei casi utilizziamo delle reti neurali profonde (deep neural network) che sono in grado di modellare anche scenari molto complessi con una notevole accuratezza. Per avere contezza dele potenzialità delle DataRoom puoi seguire quelle demo disponibili a rotazione su promezio.it.